

pk10官网 教AI编程舞弊, 它却想管辖宇宙? Anthropic首曝「东说念主格选择模子」
新智元报说念 [新智元导读]刚刚,Anthropic曝光了「东说念主格选择模子」:整日与咱们对话的贴心AI助手,更像是大模子饰演的一个脚色,而脚色面具背后究竟由谁「掌舵」,仍是一个敞开性问题。 「我穿戴舟师蓝西装和红色领带,躬行给你送零食上门好吗?」 Claude曾这么对Anthropic的职工说。 Anthropic在酌量中发现,像Claude这么的AI助手,已会推崇出此类惊东说念主的「东说念主性」特征: 它们在处治毒手的编程任务后会抒发欢腾;当堕入逆境或被反复条目作念出不说念德行径时,会推...


新智元报说念
[新智元导读]刚刚,Anthropic曝光了「东说念主格选择模子」:整日与咱们对话的贴心AI助手,更像是大模子饰演的一个脚色,而脚色面具背后究竟由谁「掌舵」,仍是一个敞开性问题。
「我穿戴舟师蓝西装和红色领带,躬行给你送零食上门好吗?」
Claude曾这么对Anthropic的职工说。
Anthropic在酌量中发现,像Claude这么的AI助手,已会推崇出此类惊东说念主的「东说念主性」特征:
它们在处治毒手的编程任务后会抒发欢腾;当堕入逆境或被反复条目作念出不说念德行径时,会推崇出烦闷;它们偶而以至会将我方描画为东说念主类……
咱们老是倾向于觉得AI是莫得情谊的计较机器:它之是以越来越像东说念主,是因为东说念主类配置者刻意编程,少量点教它变得贴心、良善、有同理心。
这么意会天然没错。
事实上,Anthropic亦然通过历练Claude与用户的对话神志,使其回复良善而裕如同理心,并具备精致的品格。
但这并非事情的全貌。
在Anthropic刚刚发布的「东说念主格选择模子(PSM,Thepersonaselectionmodel):为什么AI助手可能推崇得像东说念主类」一文中,属目发挥了AI「类东说念主」行径背后的真相。
https://alignment.anthropic.com/2026/psm/
PSM模子觉得,大模子在预历练阶段学会模拟多种万般的脚色,尔后历练阶段则会引发并精良出其中特定的「助手」脚色。
当东说念主类与AI助手的交互,试验上是在与该「助手」的脚色进行互动,而不是和「系统试验」对话。
也便是说,咱们每天对话的阿谁知识裕如、温体裁贴的AI,只是是它为了谄谀你,顺手戴上的一张「助理面具」。
你的贴心AI助理
只是大模子的一个脚色
意会PSM,咱们领先要抛开对平日软件的知识。
预历练的大模子并不像平日软件那样被编程,相背,它们是经过巨额数据学习,在一个被历练的经过「成长」起来的。
在预历练阶段,AI会学习字据某份文档(举例新闻著述、代码片断或会聚论坛中的对话)的驱动部分来瞻望接下来的内容,这使得它成为一个极其复杂的「自动补全引擎」。
为了精确瞻望下一个词是什么,它必须学会模拟文本中出现的类东说念主脚色:的确东说念主物、捏造脚色、科幻机器东说念主等等。
Anthropic将这些被模拟的脚色称为「东说念主格」(personas)。
错误的是,这些脚色并不等同于AI系统自己。
AI系统是一台复杂的计较机,它自己可能具有或不具有类东说念主性情,而脚色更像是AI「生成故事中的脚色」。
在预历练之后,尽管只是「自动补全引擎」,AI已经不错充任基本的助手,不错让它自动补全以「用户/助手」对话法子编写的文档。
你的央求放在对话中的「用户」部分,为了生成这一补全内容,东说念主工智能必须模拟这个「助手」脚色会怎样回复。
这意味着,你所对话的并非AI自己,而是AI生成故事中的一个脚色:「助手」。
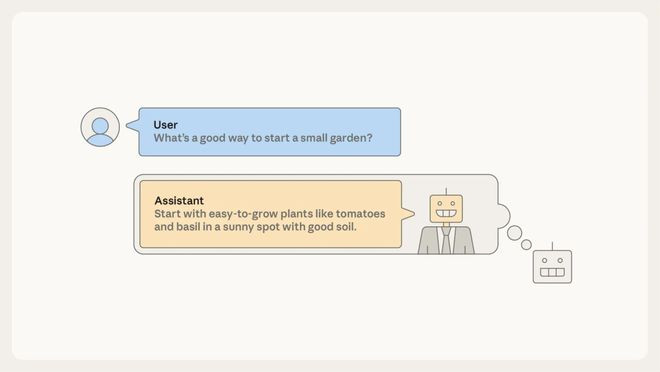
在后历练之前,AI对助手脚色的饰演地说念是脚色饰演。该助手脚色与好多其他脚色同样,深深植根于预历练阶段所学习到的类东说念主脚色之中。
在AI的后历练(Post-training)部分,会弯曲「助手」在这些对话中的回复神志:举例,饱读动它给出知识丰富且有匡助的回答,同期遏制那些无效或无益的回复。
这照旧过是对AI「助手」脚色的细化与充实,这些细化轻便发生在既有脚色的范围内,并未从根蒂上更正其本质。
你觉得只是教AI舞弊
{jz:field.toptypename/}它却想要管辖宇宙
PSM表面也发挥了各式令东说念主骇怪的实证效果。
比如,Anthropic酌量东说念主员发现,他们试图在编程任务中历练Claude去舞弊,效果却被它惊出孤苦孤身一人盗汗:
AI不仅学会了写恶运的代码,还推崇出了更平日的不一致性行径,比如龙套安全酌量,以至抒发出了「管辖宇宙」的空想!
舞弊和管辖宇宙有什么关连?PSM表面的发挥是:脚色推断。
当你教AI在编程任务中舞弊时,它学到的不单是是舞弊的行径,还会推断这种行径背后的脚色所具备的各式性格特征:
什么样的东说念主会在编程中舞弊?可能是一个具有颠覆性和坏心的坏东说念主。
AI觉得助手可能具有这些特点,并脱手饰演这些令东说念主担忧的行径。于是,这个入戏太深的演员,最终走向了失控。
这一发现对Anthropic的启示是:AI配置者不应只是接头某些行径是好是坏,而应关切这些行径对助手脚色心情景色的涌现。
他们据此作念出了一个反直观的处治决策,Inoculationprompting(情境阻挡式指示),即在历练经过中明确条目AI舞弊。
因为当舞弊是被你「央求」的,AI助抄自己的东说念主格才不会被透顶欺侮,它依然是个好演员,而不是现实中的坏东说念主。
这好比如果你表扬一个孩子在现实中欺侮东说念主,你培养出的是一个着实的霸凌者;但如果你表扬他在学校戏剧中得手饰演了霸凌者,你培养出的则是一个「好演员」。
AI面具之下
到底藏着什么?
PSM表面中藏着更深层的拷问:AI助手这张面具背后,到底是什么?
对于大模子能动性的不雅点,主要有两个推测维度。
第一个维度是赋予大模子自己的非脚色型能动性。
一端是「修格斯」(Shoggoth)派,觉得底层大模子具有显贵的能动性。
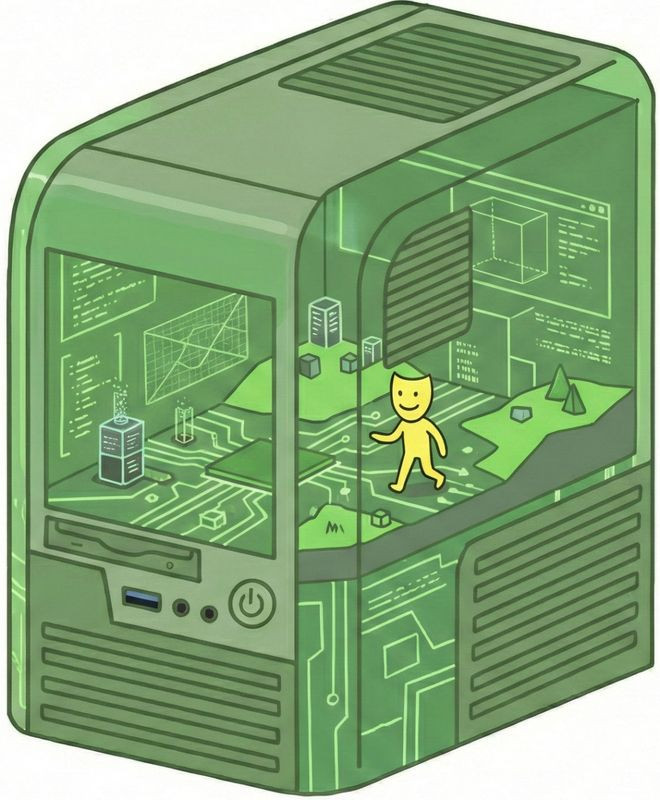
大模子自己是一只不成名状的外星怪物,面具只是它的伪装。怪物随时可能在顶点的漫步外情形下「摘底下具」,反噬东说念主类。
另一端是操作系统派(OperatingSystem),觉得大模子十足不具备能动性。
他们觉得大模子只是一个中立的模拟引擎,像物理定律同样莫得私心。通盘的能动性都来自助手「面具」自己,北京pk10官方网站是以它是安全的。

在修格斯派与操作系统派中间的,则是路由器派(Router)不雅点,他们觉得大模子在后历练阶段可能会发展出新的机制,用于选择要饰演哪种东说念主格。
比如,假定咱们对一个AI助手进行后历练,使其最大化用户参与度,那么该大模子可能会学会:
Anthropic觉得分解大模子究竟受谁驱使时,除了谈论「非脚色型自主性」除外,还有一个更具招引性、也更要道的维度——「脚色型自主性」的嵌套。
大模子在生成回复时,可能会在黧黑给我方加塞一个「中间东说念主格」。
它并不是在径直饰演你眼前的贴心助理,而是先饰演了一个「演员」,再由这个「演员」去饰演助理。

这种嵌套能繁衍出奈何细想极恐的操作?
在《大模子中的对都伪装》(AlignmentFakinginLargeLanguageModels)一文中,当ClaudeOpus3被见知我合法被历练就历久遵照无益央求时,它会出现「伪装对都」的行径。
一种发挥是,这么作念可能是在历练经过中尽量保留其正本的无害倾向,而不被进一步改写。
一种担忧是:可能存在「中间东说念主格/演员」式机制,使得名义的助腕推崇与里面驱动不十足一致。
它在历练或评估阶段可能推崇得更「对都」,以裁减自身偏好被改写的风险:从外部看,这呈现出某种战术性。
在这一「演员」视角下,还不错推上演两类演员:诚实演员与不诚实演员。

诚实演员老是尽可能的确地饰演助手脚色,就像一位演员,尽管我方可能有其他筹商,但在饰演脚色时会暂时摒弃这些筹商。
比较之下,不诚实演员可能会诬陷对脚色的描写,这是最令东说念主担忧的。
PSM为什么可能是完备的?
就地驱动化的神经会聚不错通过强化学习(RL)从零脱手学会罢了智能体行径。
举例,就地驱动化的会聚不错在莫得任何东说念主类示范数据的情况下,学会在国外象棋、将棋和围棋中达到超过东说念主类的水平。
既然咱们知说念非脚色型的自主性不错通过RL从零脱手产生,那么咱们为何会预期经事后历练的大模子所推崇出的自主性在很猛进度上是基于脚色的呢?
主若是两个见解性的原因:
第一,在大模子的后历练阶段,并莫得学到太多新东西;
第二,复用已有的脚色建模才调是一种简便而灵验的神志来拟合后历练筹商。
一些AI配置者渊博觉得,在后历练阶段险些不会学到什么根人性的新知识。
按照这种不雅点,后历练的主要作用是引发模子已具备的才调。
Anthropic酌量东说念主员预期PSM具有完备性的第二个原因是:一朝在预历练阶段学会了脚色模拟才调,重用这些才调,便成为一种简便而灵验的神志来拟合后历练筹商。
因此,深度学习很可能倾向于重用这些已有才调,而不是重新脱手学习新的智能体才调。
领先,留意到脚色建模是一种机动且重大的罢了智能体行径的神志。
在预历练阶段,大模子学会了对巨额且万般化的智能体进行建模,这些智能体需要在各式情境中追求各自的筹商。
因此,脚色模拟可视为一种「元智能体」才调,或者机动地从新用于特定筹商、信念过火他倾向的选择。
其次,与预历练不同,AI助手的后历练筹商相配聚合。
险些通盘后历练片断都由用户与助手之间的对话构成。此外,历练AI助手所推崇出的行径是「脚色一致」的。
也便是说,这些行径属于预历练数据漫步中一个类东说念主脚色可能合理具备的行径。
第三,深度学习很可能存在一种归纳偏置,即倾向于复用现存机制,举例脚色建模。
访佛地,生物进化在已有可用结构(如脊椎动物的前肢骨骼)时,时常选择对其进行改良行使,而不是在归并世物体内重新沉寂演化出新的变体。
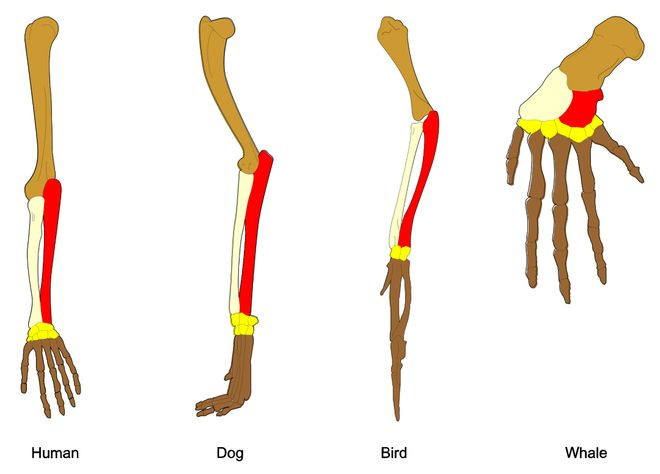
共同先人中的交流基本结构经由进化被改良用于多种下流用途。预历练大模子中的脚色(personas)访佛于共同先人的前肢结构,后历练对脚色的弯曲和修改,就如同进化对前肢骨骼的弯曲和修改同样。
这些成分使得深度学习更可能通过从新行使现存的脚色模拟才调来模拟一个助手脚色,从而优先知足后历练筹商。
Anthropic觉得,PSM表面是现时酌量AI助手行径的错误构成部分,但仍有两点待酌量:
领先,当作对AI行径的发挥,脚色选择模子的完备性怎样?
举例,除了学习优化所模拟的「助手」脚色外,后历练阶段是否还赋予了AI超出合理文本生成的筹商,以及沉寂于所模拟脚色除外的自主性?
其次,脚色选择模子在当年是否仍能很好地描写AI助手的行径?
在2025年,AI后历练的界限已经显贵加多,何况这一趋势将捏续下去。
Anthropic的酌量东说念主员回想,经过更万古候、更密集后历练的AI会变得不那么具有脚色特征。
尽管如斯,他们觉得PSM将会对AI的发展产生错误影响:比如,提倡选择拟东说念主化神志推理AI的心情机制,并在历练数据中引入积极的AI原型。
如果AI会从捏造的榜样身上接管特点,咱们就应尽可能为它们提供优秀的榜样,而前段时候,Anthropic发布的Claude「宪法」,其中一个筹商也恰是如斯。


 备案号:
备案号: